
Zorba blog
어텐션 메커니즘 (Attention Mechanism) 본문
어텐션 메커니즘 (Attention Mechanism)
- seq2seq 모델의 경우 인코더에서 입력 시퀀스를 Context Vector 라는 하나의 고정된 크기의 벡터 표현으로 압축.
- 이러한 RNN 기반의 seq2seq 모델에는 크게 두 가지 문제가 있음.
1. 하나의 고정된 크기의 Vector에 모든 정보를 압축하려고 하니까 정보 손실이 발생.
2. RNN의 고질적인 문제인 기울기 소실(Vanishing gradient) 문제가 존재.
- 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정해주기 위해 어텐션(Attention) 기법이 등장.
1. 어텐션 (Attention)의 아이디어
- 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점 마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고.
- 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(Attention)해서 보게 됨.
2. 어텐션 함수(Attention Function)
- 어텐션 메커니즘을 설명하기 위해 key-value의 개념 설명.
- 파이썬을 예로 들면 딕셔너리 자료형은 키(key) 와 값(Value) 라는 두 개의 쌍으로 구성되는데, 키를 통해서 맵핑된 값을 찾을 수 있음.
# 파이썬의 딕셔너리 자료형을 선언
# 키(Key) : 값(value)의 형식으로 키와 값의 쌍(Pair)을 선언한다.
dict = {"2017" : "Transformer", "2018" : "BERT"}print(dict["2017"]) #2017이라는 키에 해당되는 값을 출력
Transformer
print(dict["2018"]) #2018이라는 키에 해당되는 값을 출력
BERT
- 어텐션을 함수로 표현하면 다음과 같이 표현
Attention(Q, K, V) = Attention Value
- 어텐션 함수는 주어진 '쿼리(Query)에 대해서 모든 '키(Key)'와의 유사도를 각각 구함.
- 구해낸 유사도를 키와 맵핑되어있는 각각의 '값(Value)'에 반영.
- 유사도가 반영된 '값(Value)'을 모두 더해서 리턴, 이를 Attention Value라고 함.
| Q = Query : t 시점의 디코더 셀에서의 은닉 상태 K = Keys : 모든 시점의 인코더 셀의 은닉 상태들 V = Values : 모든 시점의 인코더 셀의 은닉 상태들 |
3. 닷-프로덕트 어텐션 (Dot-Product Attention)
- 어텐션은 다양한 종류가 있는데 그 중에서 닷-프로덕트 어텐션(Dot-Product Attention)을 통해 어텐션을 이해.
- 다른 어텐션과의 차이는 주로 중간 수식의 차이이며, 메커니즘 자체는 거의 유사.

- 위 그림은 디코더의 세번째 LSTM 셀에서 출력 단어를 예측할 때, 어텐션 메커니즘의 사용 예시.
- 디코더의 세번째 LSTM 셀은 출력 단어를 예측하기 위해서 인코더의 모든 입력 단어들의 정보를 다시 한번 참고.
- 인코더의 소프트맥스 함수의 결과값은 I, am, a, student 단어 각각이 출력 단어를 예측할 때 얼마나 도움이 되는지의 정도를 수치화한 값.
- 각 입력 단어가 디코더의 예측에 도움이 되는 정도를 수치화하여 측정되면 이를 하나의 정보로 담아서 디코더로 전송.
- 결과적으로, 디코더는 출력 단어를 더 정확하게 예측할 확률이 높아짐.
(이전 인코더에서의 모든 단어 중 도움되는 단어를 참고함으로.)
- 아래 설명을 통해 단계적으로 확인.
1) 어텐션 스코어(Attention Score)를 구한다.
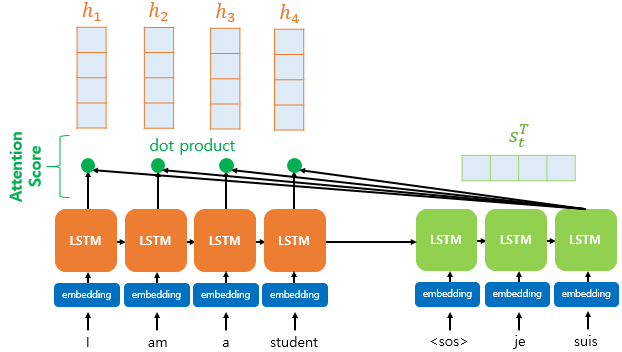
- 인코더의 시점을 각각 1,2,...,N 이라고 하였을 때 인코더의 은닉 상태를 각각 h1, h2, ..., hN 이라고 함.
- 디코더의 현재 시점 t에서의 디코더의 은닉 상태를 St 라고 함.
- 여기서는 인코더의 은닉 상태와 디코더의 은닉 상태의 차원이 같다고 가정.
- 디코더의 현재 시점 t에서 출력 단어를 예측하기 위해 이전 시점인 t-1의 은닉 상태와 t-1 시점에서 나온 출력 단어 필요.
- 어텐션 메커니즘에서는 출력 단어 예측을 위해 어텐션 값(Attention Value)를 필요로 함.
- t번째 단어를 예측하기 위한 어텐션 값을 at라고 정의.
- 지금 모든 과정은 어텐션 값(Attention Value)을 구하기 위한 여정.
- 첫 걸음은 어텐션 스코어(Attention Score)를 구하는 일.
- 어텐션 스코어란 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 은닉 상태 St와 얼마나 유사한지를 판단하는 스코어값.

- 닷-프로덕트 어텐션에서는 이 스코어 값을 구하기 위해 St를 전치(Transpose)하고 각 은닉 상태와 내적을 수행.
- 내적을 했기 때문에 모든 어텐션 스코어 값은 스칼라.
- et는 st와 인코더의 모든 은닉 상태의 어텐션 스코어의 모음값.
2) 소프트맥스(softmax) 함수를 통해 어텐션 분포(Atten Distribution)를 구한다.

- et에 소프트맥스 함수를 적용하여, 모든 값을 합하면 1이 되는 확률 분포를 얻어냄.
- 이를 어텐션 분포(Attention Distribution)라고 하며, 각각의 값은 어텐션 가중치(Attention Weight) 라고 함.
3) 각 인코더의 어텐션 가중치와 은닉 상태를 가중합하여 어텐션 값(Attention value)을 구한다.

- 어텐션의 최종 결과값을 얻기 위해서 각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고, 최종적으로 모두 더함.
4) 어텐션 값과 디코더의 t 시점의 은닉 상태를 연결한다.(Concatenate)
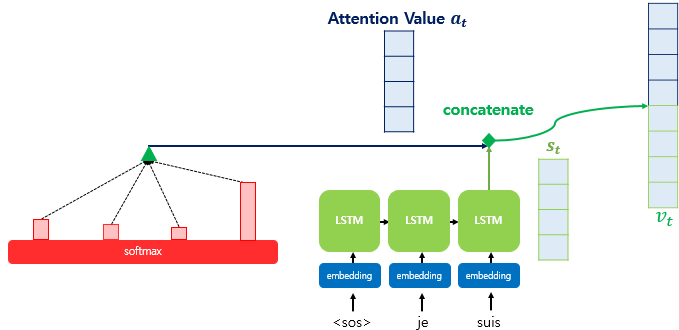
- 최종적으로 구한 어텐션 값 at를 st와 결합하여 하나의 벡터로 만드는 작업을 수행. 이를 vt라고 정의.
5) 출력층 연산의 입력이 되는 st를 계산합니다.

- vt를 바로 출력층으로 보내기 전에 신경망 연산을 한 번 더 추가.
- 가중치 행렬과 곱한 후에 하이퍼볼릭탄젠트 함수를 지나도록 하여 출력층 연산을 위한 새로운 벡터인 st를 얻음.
6) st를 출력층의 입력으로 사용합니다.
- st를 출력층의 입력으로 사용하여 예측 벡터를 얻습니다.

4. 다양한 종류의 어텐션(Attention)

'자연어처리' 카테고리의 다른 글
| NLP에서의 사전 훈련(Pre-Training) (0) | 2022.06.03 |
|---|---|
| 트랜스포머(Transformer) 모델 / 인코더, 포지션-와이즈 피드 포워드 신경망, 잔차 연결, 정규화 (0) | 2022.06.03 |
| 트랜스포머(Transformer) 모델 / 개념, 포지셔널 인코딩(Positional Encoding) (0) | 2022.06.02 |
| 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) (0) | 2022.05.31 |
| Transformer model.generate로 텍스트를 생성하는 전략들 (0) | 2022.05.19 |



