
Zorba blog
시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) 본문
시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
- seq2seq 모델은 입력된 sequence로부터 다른 도메인의 시퀀스를 출력하는 모델.
- 다양한 분야에서 활용. (ex. 챗봇, 기계 번역, 내용 요약, STT)
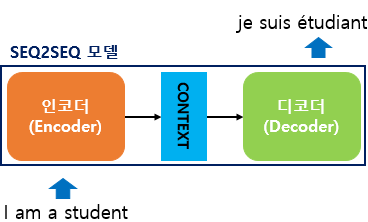
- seq2seq는 크게 인코더와 디코더라는 두 개의 모듈로 구성.
- 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받고, 마지막에 모든 단어 정보들을 압축해서 하나의 벡터로 만듬.
- 이때, 압축된 하나의 벡터를 Context Vector 라고 함.
- 디코더는 Context Vector를 받아서 번역된 단어를 한 개씩 순차적으로 출력.

- 실제 현업에서 사용되는 seq2seq 모델의 Context Vector 사이즈는 보통 수백 이상의 차원을 가짐.

- 인코더 아키텍처와 디코더 아키텍처의 내부는 각각 RNN 아키텍처.
- 입력 문장은 단어 토큰화를 통해서 단어 단위로 쪼개지고 단어 토큰 각각은 RNN 셀의 각 시점의 입력이 됨.
- 인코더 RNN 셀은 모든 단어를 입력받은 뒤에 인코더 RNN 셀의 마지막 시점의 은닉 상태를 디코더 RNN 셀로 넘겨주는데 이를 Context Vector라고 함.
- Context Vector는 디코더 RNN 셀의 첫번째 은닉 상태에 사용.
- 디코더는 기본적으로 RNNLM(RNN Language Model) 임.
[디코더의 테스트 과정]
1. 디코더는 초기 입력값으로 문장의 시작을 의미하는 심볼 <sos>가 들어가고, 그 다음에 등장할 확률이 높은 단어를 예측.
2. <sos>가 입력되면 디코더 RNN 셀은 다음에 등장할 단어로 je를 예측.
3. 이 예측된 단어 je를 다음 시점의 RNN 셀의 입력으로 사용.
4. 이 행위는 문장의 끝을 의미하는 심볼인 <eos> 가 다음 단어로 예측될 때까지 반복.
- seq2seq는 훈련 과정과 테스트 과정의 작동 방식이 조금 다름.
- 훈련 과정에서는 Context Vector의 값과 <sos> je suis etudiant 를 입력 받았을 때, je suis etudiant <eos>가 나와야 된다고 정답을 알려주면서 훈련을 진행.

- 기계는 텍스트보다 숫자를 잘 처리하기에 텍스트를 벡터로 바꾸는 워드 임베딩을 사용.
- 텍스트는 임베딩 층(Embedding Layer)을 거쳐 숫자 벡터로 변환.

- 하나의 RNN 셀은 각각의 시점마다 두 개의 입력을 받음.
- 현재 시점을 t라고 할 때, RNN 셀은 t-1에서의 은닉 상태와 t에서의 입력 벡터를 입력으로 받고, t에서의 은닉 상태를 만듬.
- 이런 구조는 현재 시점 t에서의 은닉 상태는 과거 시점의 모든 은닉상태 값들의 영향을 누적해서 받아온 값이라고 할 수 있음.
- 디코더는 인고더의 마지막 RNN 셀의 은닉 상태인 Context Vector를 첫 번째 은닉 상태의 값으로 사용.
- 디코더의 첫번째 RNN 셀은 Context Vector의 값과 <sos>로부터, 다음에 등장할 단어를 예측.

- 디코더의 출력으로 나올 수 있는 단어들은 다양한 단어들이 있음.
- seq2seq 모델은 소프트맥스 함수를 사용하여 선택될 수 있는 모든 단어들로부터 하나의 단어를 골라서 예측해야 함.
- 디코더의 각 시점의 RNN 셀에서 출력 벡터가 나오면, 소프트맥스 함수를 통해 출력 시쿼스의 각 단어별 확률값을 반환하고, 출력 단어를 결정.
교사강요(Teacher forcing)
- 디코더의 아키텍처를 보면 현재 시점의 디코더 셀 입력은 이전 디코더 셀의 출력을 입력으로 받는다고 설명되어 있음.
(2번째 시점의 입력은 1번째 시점의 출력인 je)
- 테스트 과정에서는 이전 시점의 출력을 다음 시점의 입력으로 그대로 사용.
- 훈련 과정에서는 이전 시점의 출력이 무엇이든지 상관 없이 다음 시점의 입력은 이전 시점의 실제값을 넣음.
- 그 이유는 이전 시점의 디코더 셀의 예측이 틀렸는데 이를 현재 시점의 디코더 셀의 입력으로 사용한다면 현재 시점의 디코더 셀의 에측도 잘못될 가능성이 높고, 연쇄 작용으로 디코더 전체의 예측을 어렵게 하게 됨.
- 이런 상황이 반복되면 훈련 시간도 느려짐.
- 따라서 이전 시점의 디코더 셀의 예측값 대신 실제값을 현재 시점의 디코더 셀의 입력으로 사용하고, RNN의 모든 시점에 대해서 이전 시점의 예측값 대신 실제값을 입력으로 주는 방법을 교사 강요라고 함.
'자연어처리' 카테고리의 다른 글
| NLP에서의 사전 훈련(Pre-Training) (0) | 2022.06.03 |
|---|---|
| 트랜스포머(Transformer) 모델 / 인코더, 포지션-와이즈 피드 포워드 신경망, 잔차 연결, 정규화 (0) | 2022.06.03 |
| 트랜스포머(Transformer) 모델 / 개념, 포지셔널 인코딩(Positional Encoding) (0) | 2022.06.02 |
| 어텐션 메커니즘 (Attention Mechanism) (0) | 2022.05.31 |
| Transformer model.generate로 텍스트를 생성하는 전략들 (0) | 2022.05.19 |



