
Zorba blog
Transformer model.generate로 텍스트를 생성하는 전략들 본문
요즘 KoBart 모델을 사용하여 요약문을 생성하는 작업을 하고있다.
원문을 입력으로 받고, 토크나이저로 인코딩 작업을 한 다음에 디코딩 과정에서 요약문을 생성하게 되는데
문장을 생성하는 과정에서 어떠한 전략들이 있는지 확인해보았다.
문장을 생성하는 작업을 할 때, 트랜스포머 아키텍처, 대용량의 비지도 학습 데이터
뿐만 아니라 디코딩 방법에 따라서도 문장 생성의 성능이 확연히 달라질 수 있다.
아래 소개하는 방법들은 아래와 같이 표현할 수 있는 Auto-Regressive 언어 모델에 적용이 가능하다.
Auto-Regressive
Auto-Regressive 언어 모델이란 Word Sequence의 확률 분포에 근거한다. 즉, 문장의 확률값을 연속적으로 구하듯이 이전의 단어들로 다음 단어의 확률을 예측하면서 문장을 생성하는 방식을 말한다.

아래에서부터 디코딩 방식으로 Greedy Search, Beam Search, Top-K 샘플링, Top-P 샘플링을 알아보자.
1. Greedy Search
- Greedy Search는 단순히 가장 높은 확률로 나온 다음 단어를 선택하는 것이다.
- 아래 캡처본을 보면 알겠지만 각 시점 t마다 가장 높은 확률을 선택한다.
- "The" 부터 시작하여 알고리즘은 가장 높은 확률의 다음 단어를 선택한다.
- 다음으로 "nice" 가 선택되고, 마침내 ("The", "nice", "woman") 이 선택되어 문장을 생성한다.

아래는 Greedy Search 코드이다. input_ids, max_length 외에 추가사항은 없다.
# 생성할 텍스트의 시작 문구 지정
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# 디코딩 최대 길이 50글자까지 model generate를 통해 디코딩 진행
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll- 생성된 문장이 합당해 보이기는 한다. 하지만 모델이 너무 반복된 문장들을 생성하는 경향이 있다.
- 이러한 동어 반복 문제는 언어 모델에서 흔한 문제인데 특히 Greedy, Beam Search 에서 자주 발생한다.
- 또한 가장 높은 확률의 단어를 선택하는 것이 완성된 문장의 관점에서는 가장 적합한 문장이 아닐 수 있다.
지금 The -> Nice(0.5) -> Word(0.4) 인 경우에는 각자의 상황에서 가장 높은 확률을 선택했기 때문에 0.5*0.4=0.2가 된다. 만약에 Nice 대신에 dog(0.4)와 has(0.9)를 선택했다면? 0.4*0.9=0.36 이라는 더 좋은 문장을 만들 수도 있었을 것이다.
2. Beam Search
- Beam Search는 Greedy Search의 단점을 보완하기 위해 고안한 방법이다.
- 가장 가능성 있는 num_beams개의 Sequence를 유지하고, 최종적으로 가장 높은 확률의 문장을 선택한다.
- 언제나 Greedy Search 보다는 높은 확률의 문장을 찾게 되지만, 여전히 최선의 아웃풋을 보장하지는 않는다.

위의 예시는 num_beams=2로 디코딩 할 때의 예시를 보여준다. The 다음으로 dog, nice, car 중 가장 높은 확률 2개의 단어를 선택하여 시퀀스를 유지한다. The dog, The nice. 다음 타임 스텝에서는 The dog has, The nice woman이 선택되고, Greedy Search와는 달리 The dog has 시퀀스가 선택된다.
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))- early_stopping 을 True로 설정하면, EOS 토큰(End of Sequence) 이 나오는 경우 생성을 중단한다.
2-1. n-gram 패널티
- 출력에 동어 반복이 발생하는 경우 n-gram 패널티를 도입할 수 있습니다.
- n-gram 패널티를 사용하면 n번 이상의 단어가 반복되는 경우 임의로 단어의 확률을 0으로 설정하여 두 번 나타나지 않도록 합니다.
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2, #이걸로 설정 할 수 있습니다.
early_stopping=True
)이 방법이 반복 단어를 없애기 때문에 문장 생성 측면에서는 좋을 수 있으나 상황에 따라 주의가 필요하다. 만약에 New York에 대해 생성된 기사에서 2-gram 패널티를 사용하게 된다면 전체 텍스트에서 New York이 한 번만 나타나기 때문이다.
2-2. Beam Search 에서 k개의 결과 모두 리턴하기
- Beam Search 결과에서 디코딩한 시퀀스 중 가장 높은 확률의 문장 k개를 모두 리턴할 수 있다.
- 상황에 따라 k개의 결과 중 가장 마음에 드는 것을 선택하면 된다.
- num_return_sequences 옵션을 통해 구현 가능하며, num_beams 값 보다는 작거나 같아야 한다.
# set return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5, #5개의 beam search 결과물 축력
early_stopping=True
)Open-Ended Generation(모델이 자유롭게 글을 생성하는 모델) 에서는 Beam Search가 최선의 방법이 아닐 수 있다.
- 기계번역이나 요약처럼 문장의 길이가 제한되어 있거나 예측 가능한 경우에는 Beam Search가 잘 작동.
- 일기나 스토리를 생성하는 Open-Ended Generation인 상황에서는 Beam Search가 잘 작동하지 않는다는 연구 결과.
- Beam Search 에서는 동어 반복 문제가 심하다. 그런데 만약 스토리 생성을 하는 경우 특정 단어들에 대해서는 적절한 반복이 필요한 경우가 있다. 이처럼 n-gram 이나 다른 페널티를 적용하는 것과 적절히 필수적인 단어들은 반복되어야 하는 Trade off 가 발생한다.
- Beam Search의 방법과 인간이 사용하는 언어에는 차이점이 있다. 인간은 너무 예측 가능한 뻔한 단어를 생성하지 않고, 가끔 뜻밖의 단어가 뒤에 나오고는 한다.
- 그래서 문장 생성을 하는 경우, 지루함을 타파하고자 랜덤성을 부여한다!
3. Sampling
- Sampling은 다음에 올 단어에 대한 확률분포에 따라 단어를 샘플링하는 방식을 말한다.
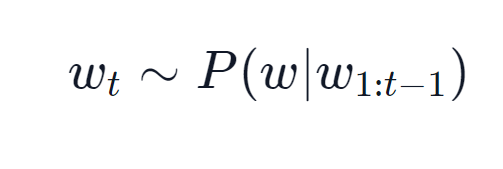
- 이 방법은 더이상 문장을 결정적으로 생성하지 않는다. 샘플링 방식으로 확률에 기거해 단어를 뽑기 때문이다.

- do_sample=True로 설정하면 샘플링을 사용할 수 있다. top_k=0 으로 설정하면 타임스텝별로 하나의 토큰만 샘플링한다.
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)- 만약 다음 단어의 확률들이 전부 비슷하거나, 높은 확률을 가진 단어가 없다면 낮은 확률의 토큰이 너무 지나치게 샘플링 될 수 있고, 이에따라 어색한 문장이 만들어질 수 있다.
- 이를 방지하기 위해 높은 값을 가지는 확률을 더 뾰족하게 만드는 "temperature" 스케일링(Softmax함수)을 사용한다.

- 코드에서는 temperature 옵션을 조절하여 확률의 뾰족함을 조절할 수 있다.
- temperature이 0에 가까워질수록 가장 높은 확률을 선택했던 Greedy Search에 가까운 문장이 생성된다.
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# use temperature to decrease the sensitivity to low probability candidates
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)- top_k를 0으로 설정하면 타임스텝별로 하나의 토큰만 샘플링 한다.
4. Top-K Sampling
- Sampling을 할 때, Top K개의 단어들만을 대상으로 Sampling을 진행하는 방법이다.
- Top-K를 뽑는 이유는 만에하나 1%의 확률로 이상한 단어가 선택될 가능성을 배제하기 위해서이다.
- 아래 예를 보면 K=6 으로 셋팅한 Top-K 샘플링 결과를 보여준다.

- 첫번째 타임스텝에서는 0.68정도에 해당하는 단어에서 디코딩을 진행하고, 두 번째 에서는 너무 이상한 토큰들을 제외할 수 있다.
- 코드에서 top_k 를 통해 설정할 수 있다.
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# set top_k to 50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)- 하지만 이 방법도 K개의 단어를 효과적으로 활용하지 못 할 수 있다는 단점이 있다.
- 왼쪽의 예시를 보면 평평한 분포에서 샘플링을 하지만 오른쪽의 경우 매우 샤프한 분포에서 샘플링을 진행한다.
- 왼쪽의 경우 꽤 괜찮았던 단어 후보군들이 샘플링 대상에서 제외되어 버린다.
- 오른쪽의 경우 매우 낮은 확률의 단어들이 억지로 포함되어 확률이 이전보다 올라가게 된다.
- 즉, 왼쪽의 경우 모델의 다양성,창의성이 떨어지게 되고, 오른쪽의 경우 이상한 단어를 샘플링할 위험성이 커지게 된다.
5. Top-p (nucleus) Sampling
- Sampling을 Top K 개에 대해서 진행하는 것이 아니라, Top K 개의 확률 누적값이 일정 값 P 이상이 되도록 하는 K개의 단어를 샘플링 후보로 선정하는 방법이다.
- 가장 높은 확률을 가지는 토큰부터 시작하여 확률 값의 합이 P를 넘을 때까지 샘플링 대상에 토큰을 추가한다.
- 이렇게하면 Top-k의 단점을 보완할 수 있다.

- 왼쪽을 보면 아까는 K개를 선택해야 해서 빠졌던 단어들이 다시 샘플링 대상으로 포함되는 것을 볼 수 있다.
- 오른쪽을 보면 아까는 K개를 선택해야 해서 억지로 추가했던 단어들이 샘플링 대상에서 제외되는 것을 볼 수 있다.
- 코드에서는 top_p 값을 0~1사이에서 선택하면 된다.
tf.random.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92, #92%로 설정하고 샘플링하기
top_k=0
)- top-p 샘플링이 더 좋아보이기는 하지만 top-k, top-p 둘 다 모두 잘 작동한다.
- 두 전략을 섞으면 다양한 문장을 생성할 수 있다.
결론
- 인간의 평가에 따르면 Beam Search가 Top-p sampling 방법보다 보다 유창한 문장을 생성하기도 한다.
- 상황마다 무조건 좋은 방법은 없기 때문에 다양한 방법을 실험해보며 적합한 전략을 선택하는 것이 중요하다.
- Open-ended 생성에서는 Top-K 혹은 Top-P 디코딩이 greedy or Beam Search 보다 좋은 전략일 수 있다.
참고
'자연어처리' 카테고리의 다른 글
| NLP에서의 사전 훈련(Pre-Training) (0) | 2022.06.03 |
|---|---|
| 트랜스포머(Transformer) 모델 / 인코더, 포지션-와이즈 피드 포워드 신경망, 잔차 연결, 정규화 (0) | 2022.06.03 |
| 트랜스포머(Transformer) 모델 / 개념, 포지셔널 인코딩(Positional Encoding) (0) | 2022.06.02 |
| 어텐션 메커니즘 (Attention Mechanism) (0) | 2022.05.31 |
| 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) (0) | 2022.05.31 |



