
Zorba blog
Convolutional Neural Network(CNN) 본문
CNN의 등장 배경
전연결 신경망(Fully Connected Neural Network, FCNN)의 한계
- Fully Connected Layer 만으로 구성된 인공 신경망의 입력 데이터는 1차원 배열 형태로 한정.
- 한 장의 컬러 사진은 RGB 값을 갖는 3차원 배열, 배치 모드에 사용되는 여러 장의 사진은 4차원 배열 형태.
- Image Data로 전연결 신경망을 학습시켜야 할 경우 3차원 데이터를 1차원으로 평면화 시키는 과정이 선행되어야 함.
- 이 과정에서 공간 정보가 손실, 특징 추출과 학습이 비효율적.
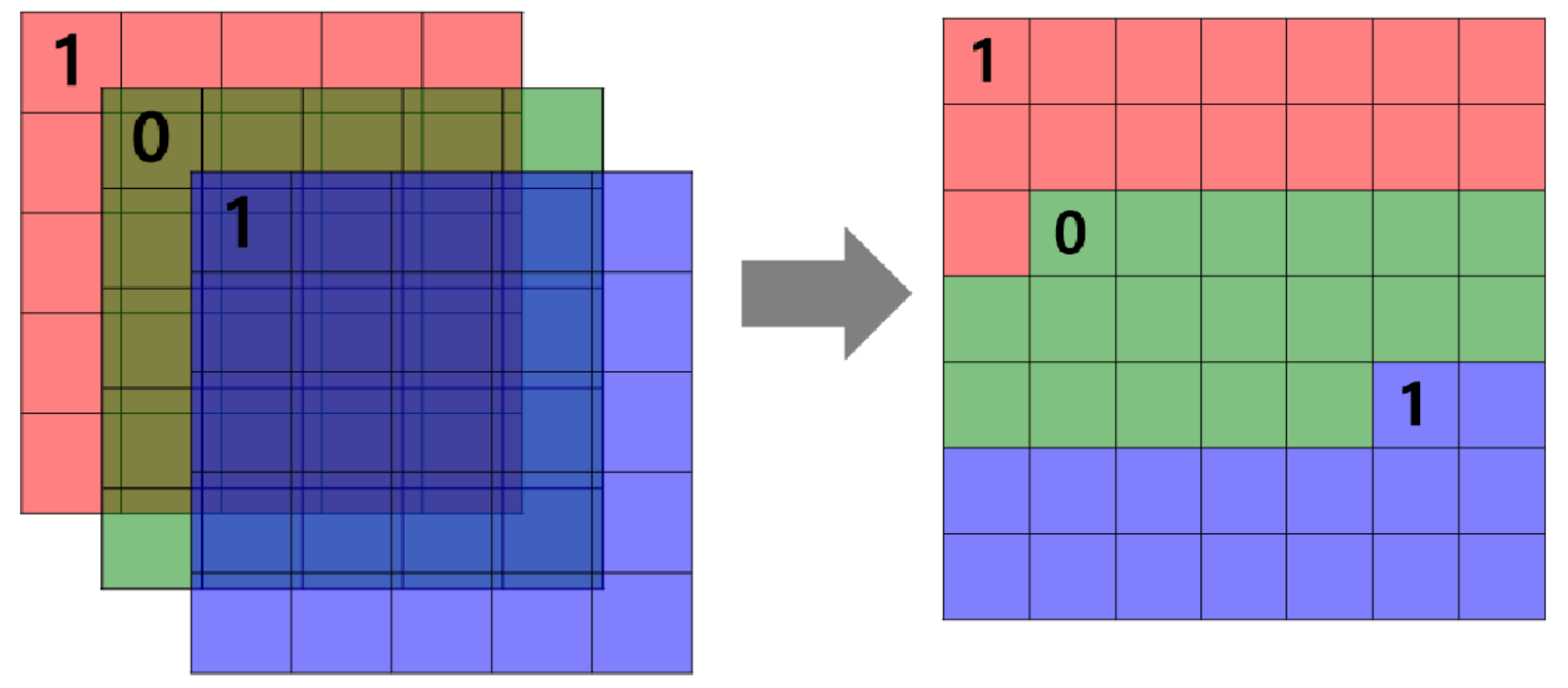
- 이미지의 공간 정보를 유지한 상태로 학습이 가능한 모델의 필요성이 대두되어 합성곱 신경망이 탄생.
- CNN(Convolutional Neural Network)은 기존의 FCNN에 대하여 다음과 같은 차별점을 가짐.
- 각 레이어의 입출력 데이터 형상 유지.
- 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식
- 복수의 필터로 이미지의 특징 추출 및 학습
- 추출한 이미지를 모으고 강화하는 Pooling Layer
- 필터를 공유 파라미터로 사용하므로, 일반 인공 신경망과 비교하여 학습 파라미터가 매우 적음.
CNN의 기본 구조
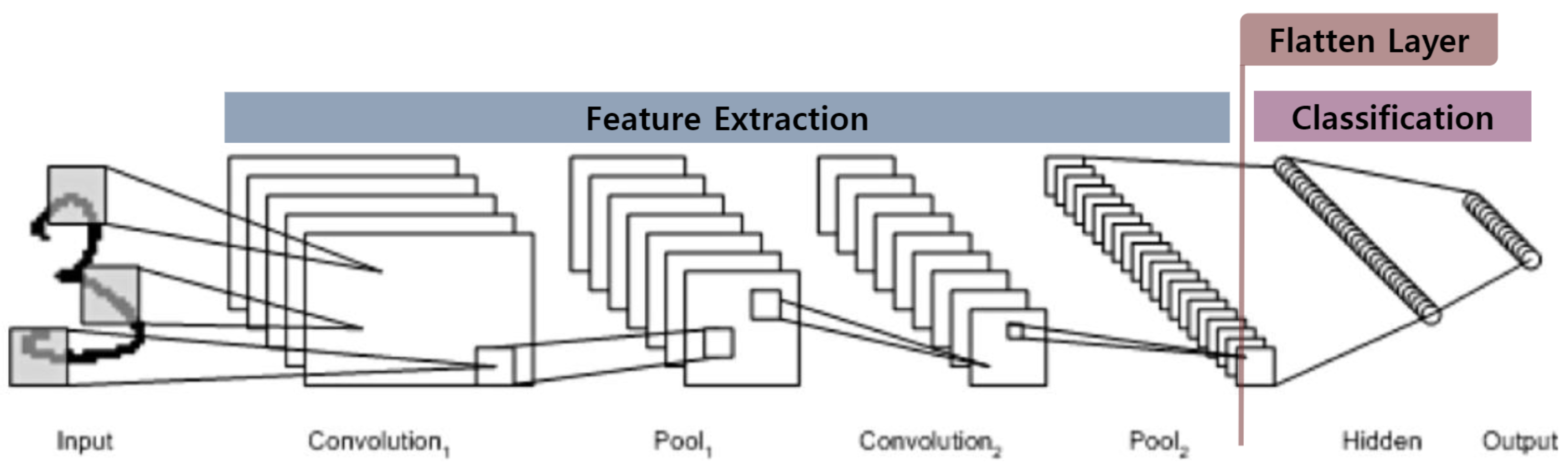
특징 추출(Feature Extraction)과 분류(Classification) 영역
특징 추출 영역 : Convolution Layer와 Pooling Layer를 겹쳐 쌓는 형태
분류 영역 : FC Layer로 구성
- 특징 추출 영역과 분류 영역 사이에 이미지 형태의 데이터를 배열 형태로 만드는 Flatten Layer 위치.
CNN 용어 정리
1) 컨볼루션(Convolution). 합성곱
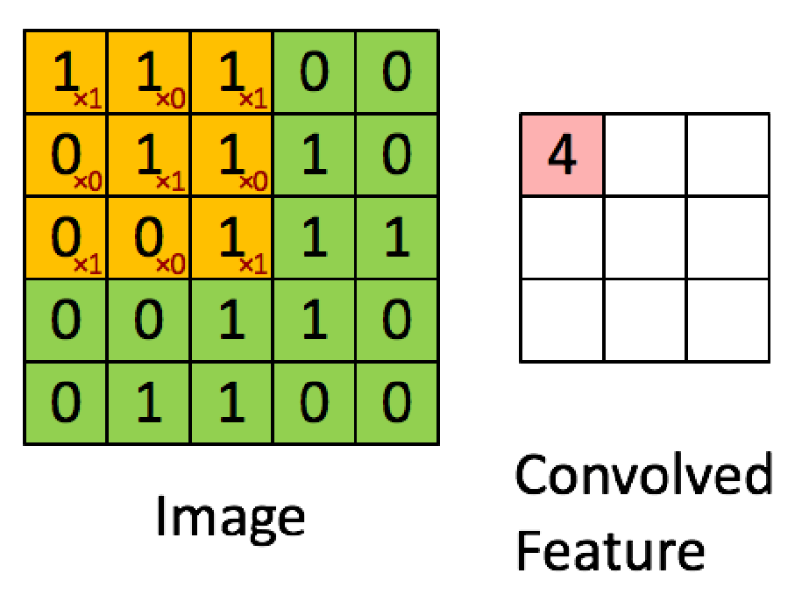
- 컨볼루션 레이어의 뉴런은 입력 이미지의 모든 픽셀에 연결되는 것이 아니라 뉴런의 수용영역(Receptive Field) 안에 있는 픽셀에만 연결.
- 초반의 컨볼루션 레이어에서는 저수준 특정에 집중하고, 후반에는 고수준 특정으로 조합하도록 동작.
합성곱 : 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음. 구간에 대하여 적분하여 새로운 함수를 만드는 것.

매우 유사한 연산으로 교차 상관(Cross-Correlation)이 있음.
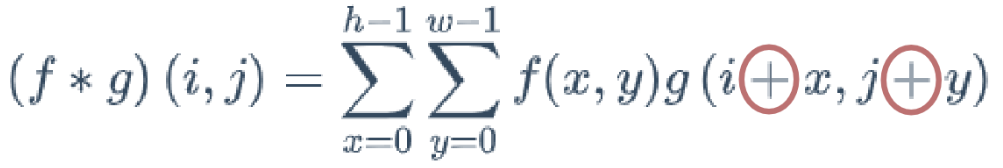
- 합성곱과 교차 상관의 차이는 한 함수를 반전하는지 여부의 차이 뿐.
- CNN에 합성곱을 적용하려면 필터의 값을 반전시켜 연산해야 함.
- CNN의 목표는 필터의 값을 학습하는 것이므로 학습 단계와 추론 단계에서 일관된 필터 값을 사용한다면 반전 여부는 중요치 않음.
- 필터를 반전시키는 데 걸리는 연산량과 시간 소요를 줄이기 위하여 Tensorflow를 비롯한 다른 딥러닝 프레임워크들은
합성공 대신 교차 상관을 사용하여 컨볼루션 레이어를 구현.
2) 필터(Filter)
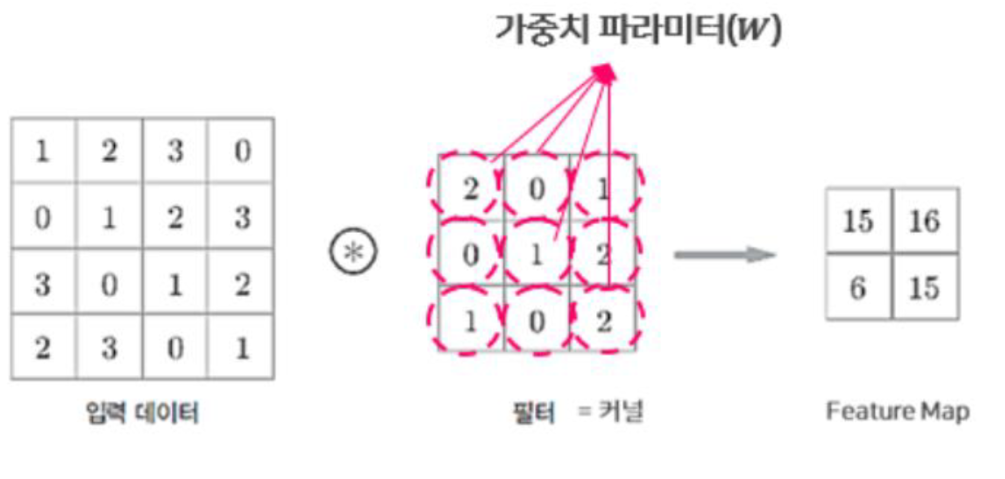
- 앞어 뉴런의 수용영역(Receptive Field)를 결정하는 것이 필터.
- 커널(Kernel)이라고도 하며, 컨볼루션 레이어의 가중치 파라미터 W에 해당.
- 필터와 유사한 이미지의 영역을 강조하는 특성 맵(Feature Map)을 출력하여 다음 레이어로 전달.
3) 채널(Channel)
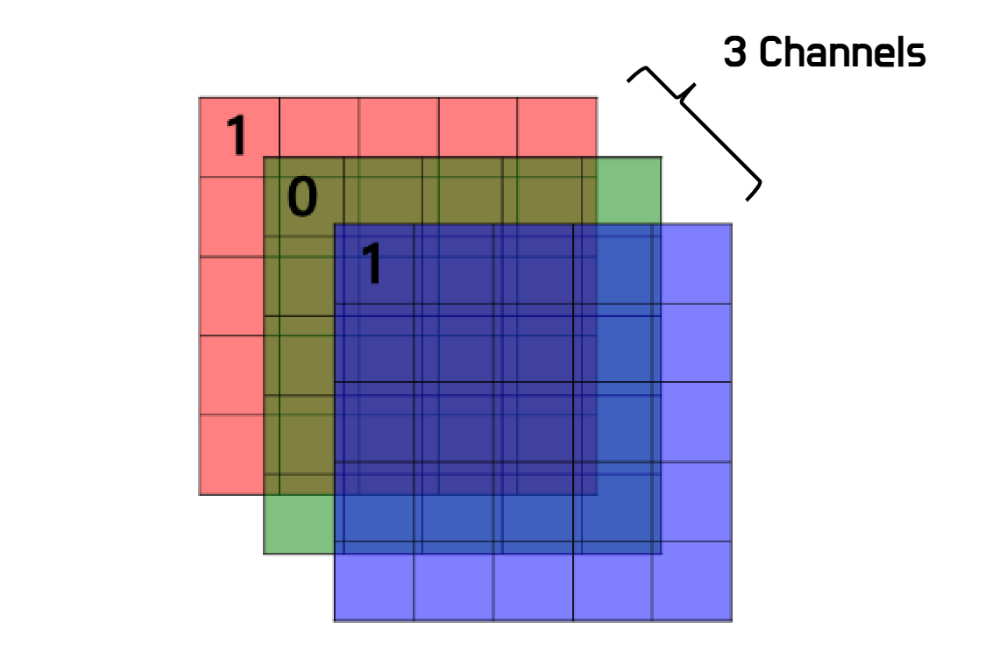
- 컬러 이미지는 3개 채널로 구성(R,G,B)
- 흑백 이미지는 1개 채널
- 입력 데이터와 필터의 채널 수를 일치시켜야 함.
4) 패딩(Padding)

- 합성곱 연산 수행 전, 입력 데이터 주변을 특정 값으로 채워 늘리는 것.
- 데이터의 공간적(Spatial) 크기는 컨볼루션 레이어를 지날 때 마다 작아지므로 가장자리의 정보가 사라지는 문제 발생.
- 이 문제를 해결하기 위해 출력 데이터의 공간적 크기를 조절하는 것이 목적. 주로 입력 데이터의 크기와 동일하도록 조정.
- 주로 0으로 채우는 Zero-Padding 사용.
5) 스트라이드(Stride)

- 입력 데이터에 필터를 적용할 때 필터가 이동할 간격.
- 출력 데이터의 크기 조절이 목적.
- 보통 1과 같이 작은 값이 더 잘 작동하며 스트라이드가 1일 경우 입력 데이터의 공간적 크기는 풀링 레이어에서만 조절.
6) 풀링(Pooling) 레이어
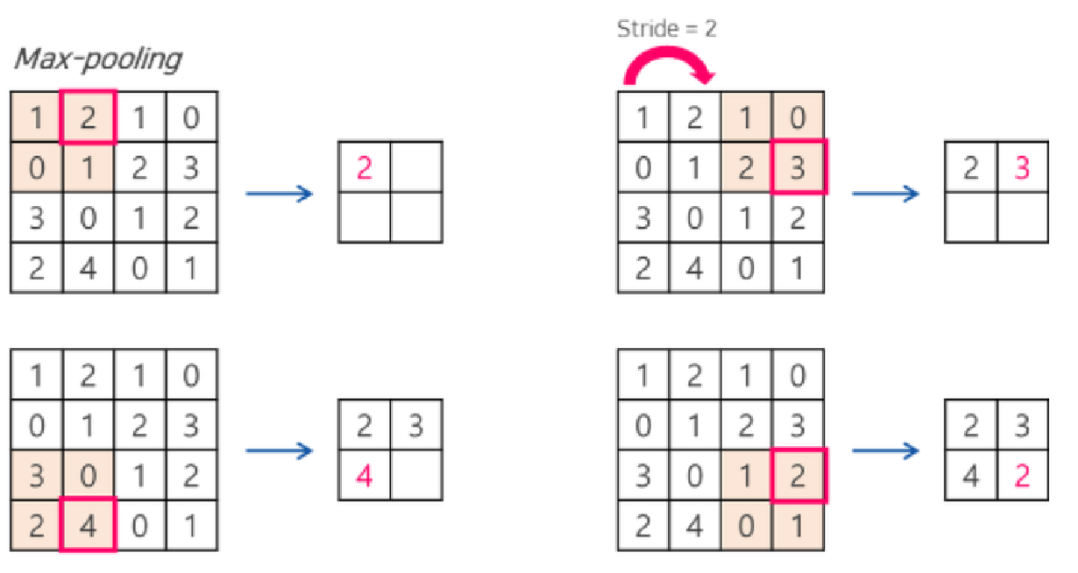
- 컨볼루션 레이어의 출력을 입력으로 받아 출력 데이터의 크기를 줄이거나 특정 데이터를 강조하기 위해 사용.
- Max Pooling, Average Pooling, Min Pooling 등의 방식이 있으나 이미지 처리에서는 Max Pooling을 주로 사용.
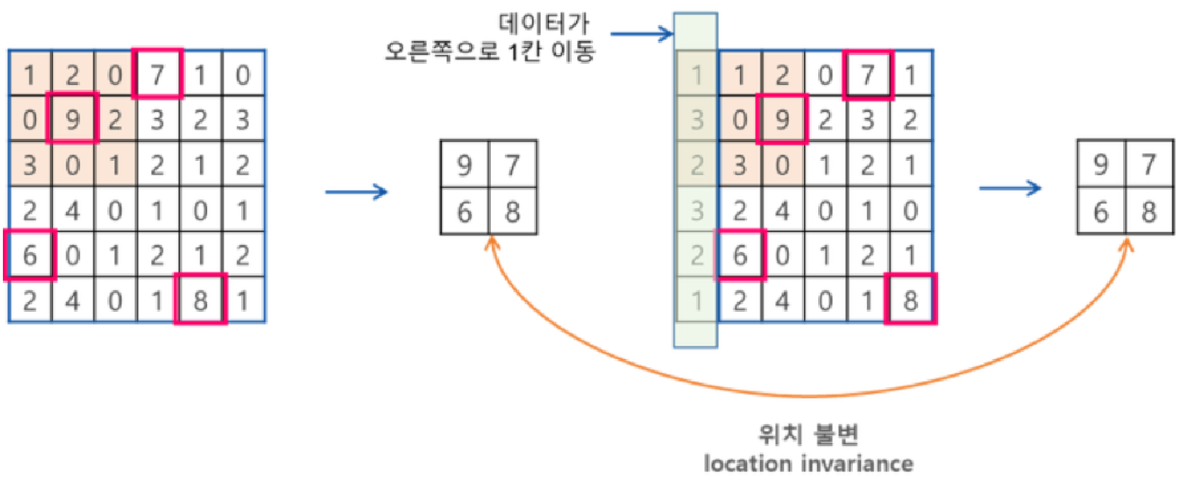
- 풀링을 통해 계산한 이미지의 특징은 이미지 내의 위치에 대한 변화에 영향을 덜 받음.
- 이처럼 풀링을 통해 찾고자 하는 특징의 불변성(Invariance)를 발견하여 공간적 변화를 극복할 수 있음.
- 물론 처리되는 데이터의 양과 모델의 전체 매개변수의 수를 줄일 수 있는 기술적인 장점도 존재.
7) 피쳐 맵(Feature Map)
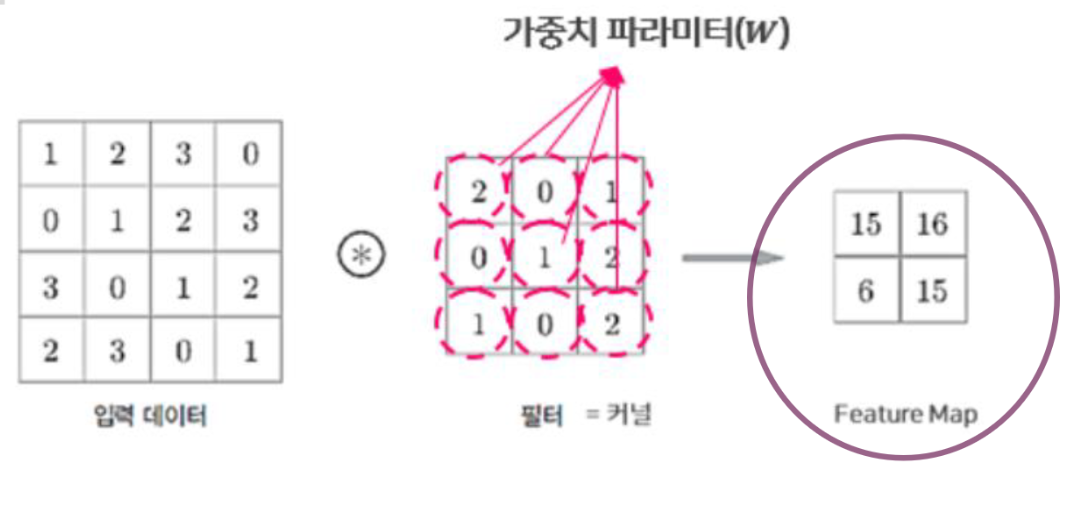
- CNN에서는 입력 데이터와 출력 데이터의 형상이 동일하게 유지됨.
- 특성 맵(Feature Map)은 레이어의 출력 데이터.
- 활성 맵(Activation Map) 이라고도 지칭
- 필터의 가중치 값을 기준으로 연산하여 필터와 유사한 이미지의 영역이 강조된 형태.
CNN 레이어 출력 크기 계산
- 패딩과 스트라이드를 적용하고, 입력 데이터와 필터의 크기가 주어졌을 때 출력 데이터의 크기를 구하는 식.

- (H, W) : 입력 데이터의 Height, Width Size
- (FH, FW) : 필터의 Height, Width Size
- S : 스트라이드(Stride)
- P : 패딩(Padding)
- (OH, OW) : 출력 데이터의 Height, Width Size

3차원 데이터에 대한 CNN
- 입출력 데이터를 직육면체의 블록으로 생각하면 이해하기 편함.
- 3차원 데이터는 (Height, Width, Channel) 순으로 표현.
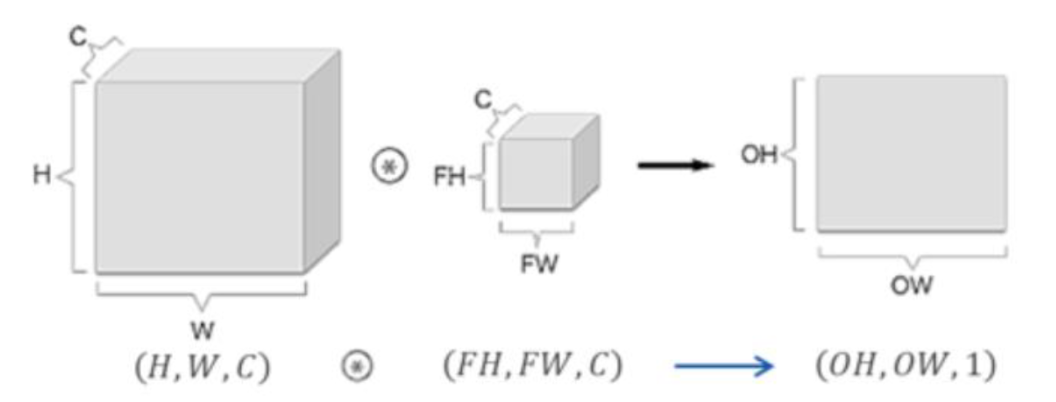
- 3차원 입력 데이터에 대하여 하나의 필터로 합성곱 연산을 수행하면 하나의 채널을 가지는 특성 맵이 출력.
- 여러 개의 채널을 갖는 특성 맵을 출력하기 위해서는 여러 개의 필터를 사용해야 함.
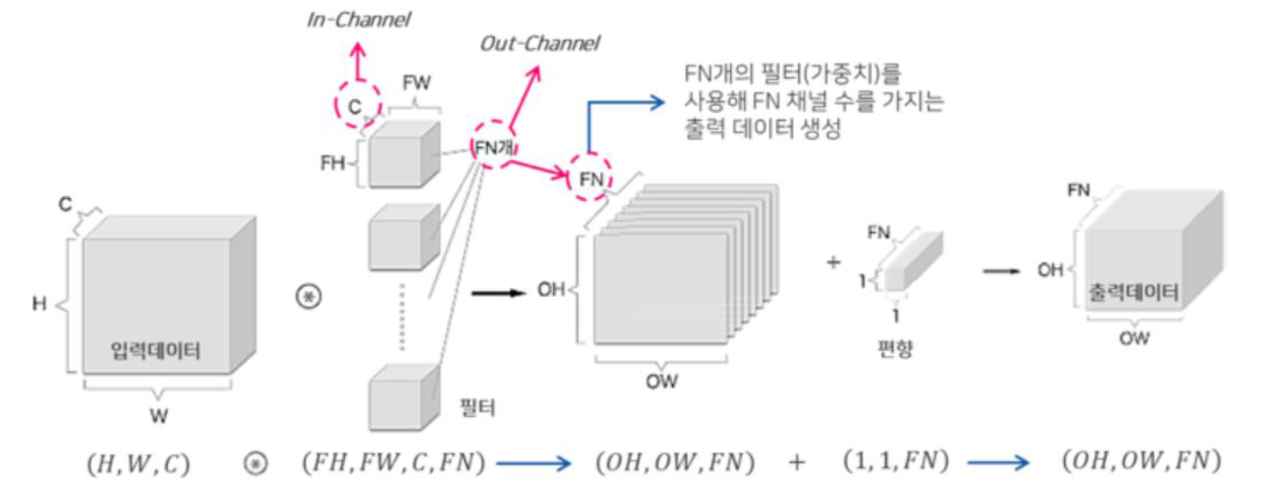
- 컨볼루션 레이어의 학습 파라미터 수 : C x FH x FW x FN
CNN과 FCNN의 비교
1. CNN
- 4개의 컨볼루션 레이어, 39x31x1 크기의 입력 데이터, 100개의 클래스로 분류.
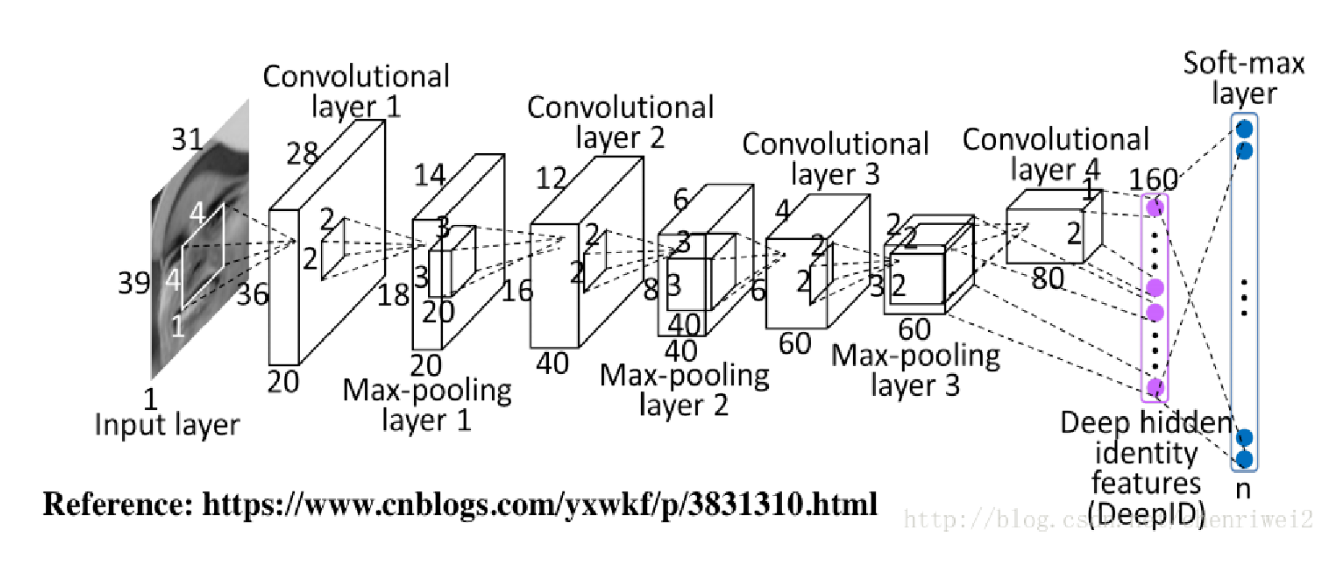
2. FCNN
- 4개의 dmsslrcmd, 1209x1(39x31x1) 크기의 입력 데이터, 100개의 클래스로 분류.

- FCNN의 총 파라미터는 100만 개가 넘어감
- CNN의 경우 20만개로 5배 이상의 차이
- 은닉층이 깊어질 경우 이 차이는 거 급격히 늘어남
-> 때문에 CNN은 FCNN과 비교하여 학습이 쉽고, 네트워크 처리 속도가 빠름.
출처 : https://github.com/sooftware/Speech-Recognition-Tutorial/blob/master/seminar/CNN.pdf
'Machine Learning' 카테고리의 다른 글
| RNN(Recurrnet Neural Neetwork) (0) | 2022.08.06 |
|---|---|
| LSTM and GRU(Long Short Term Memory & Gated Recurrent Unit) (0) | 2022.08.06 |
| Gradient Descent Optimization Algorithms (0) | 2022.06.23 |
| 앙상블(Ensemble) / Bagging, Boosting, Stacking (0) | 2022.06.22 |
| 서포트 벡터 머신 (Support Vector Machine, SVM) (0) | 2022.05.16 |

