
Zorba blog
Word Embedding(ELMo, BERT) 본문
ELMo and BERT
- 언어 모델의 성능 향상을 위하여 모델의 가장 핵심이라 할 수 있는 워드 임베딩(Word Embedding) 방식을 개선하려는 시도가 있었음.
- 2018년, ELMo와 BERT가 제안되며 NLP(Natural Language Processing) 분야의 트렌드를 주도함.
기존 Word Embedding 방식의 문제점
- 주변 맥락 단어를 학습할 때만 고려하고, 이렇게 생성된 어휘 임베딩을 다른 모델의 입력으로 사용하는 상황은 가정하지 않음.
- 즉, 학습이 완료된 후 어휘 임베딩 값은 불변.
- 실제로 사용되는 어휘의 의미는 맥락에 따라 가변적임.
- "나는 머리를 끄덕였다."
- "나는 머리를 다시 잘랐다."
- "나는 머리가 좋아서 공부를 잘 한다."
- 기존 임베딩 방식은 위의 세 가지 '머리' 단어에 대하여 같은 임베딩 값을 할당.
- 학습이 잘 이루어졌다면 위의 세 가지 상황에 대한 맥락적 정보를 모두 포괄할 것이나,
- 실제 사용되는 맥락과 관계 없는 정보까지 담고 있어야 하며, 이러한 정보는 사실상 불필요함.
ELMo(Embedding from Language Models)
- ELMo의 가장 큰 특징은 사전 훈련된 언어 모델(Pre-Trained Language Model)을 사용한다는 점.
- 사과라는 단어를 보면 "미안해서 사과하다."와 "사과를 먹다."에서의 사과는 전혀 다른 의미를 가짐.
- Word2Vec 이나 GloVe 등으로 표현된 임베딩 벡터들은 이를 제대로 반영하지 못한다는 단점이 있음.
- 같은 표기의 단어라도 문맥에 따라서 다르게 워드 임베딩을 할 수 있으면 자연어 처리의 성능이 올라갈 것.
- 워드 임베딩 시 문맥을 고려하여 임베딩을 하겠다는 아이디어가 문맥을 반영한 워드 임베딩
(Contextualized Word Embedding)
biLM(Bidirectional Language Model)의 사전 훈련
- 다음 단어를 예측하는 작업인 언어 모델링을 보자. 아래는 은닉층이 2개인 일반적인 단방향 RNN 언어 모델.
- RNN 언어 모델은 문장으로부터 단어 단위로 입력을 받고, RNN 내부의 은닉상태 ht는 시점이 지날수록 업데이트 됨.
- 이는 결과적으로 RNN의 ht의 값이 문장의 문맥 정보를 점차적으로 반영한다고 말할 수 있음.
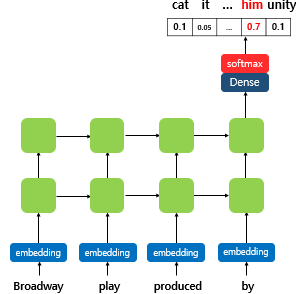
- ELMo는 위의 그림의 순방향 RNN 뿐만 아니라, 위의 그림과는 반대 방향으로 문장을 스캔하는 역방향 RNN 또한 활용.
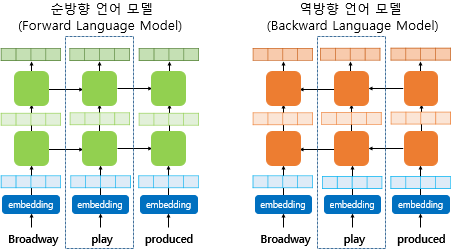
- 양쪽 방향의 언어 모델을 둘 다 학습하여 활용한다고하여 이 언어 모델을 biLM(Bidirectional Language Model)이라 함.
- 양방향 RNN과 ELMo에서의 biLM은 다름. 양방향 RNN은 순방향 RNN의 은닉 상태와 역방향 RNN의 은닉 상태를 연결(concatenate)하여 다음층의 입력으로 사용. 반면, biLM은 순방향 언어모델과 역방향 언어모델이라는 두 개의 언어 모델을 별개의 모델로 보고 학습.
biLM의 활용
- biLM이 언어 모델링을 통해 학습된 후 ELMo가 사전 훈련된 biLM을 통해 입력 문장으로부터 단어를 임베딩하기 위한 과정.
- play라는 단어를 임베딩 하기위해서 ELMo는 위의 점선의 사각형 내부의 각 층의 결과값을 재료로 사용.
- 해당 시점의 BiLM의 각 층의 출력값을 가져오고, 순방향, 역방향 언어 모델의 각 층의 출력값을 연결하여 추가 작업 진행.
- 각 층의 출력값이란 첫번째는 임베딩 층. 나머지 층은 각 층의 은닉 상태를 말함.
* ELMo의 직관적인 아이디어는 각 층의 출력값이 가진 정보는 전부 서로 다른 종류의 정보를 갖고 있을 것이므로, 이들을 모두 활용한다는 점.
1) 각 층의 출력값을 연결한다.
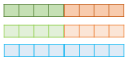
2) 각 층의 출력값 별로 가중치를 준다.
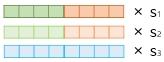
3) 각 층의 출력값을 모두 더한다.
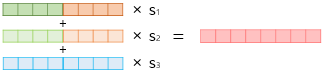
4) 벡터의 크기를 결정하는 스칼라 매개변수를 곱한다.
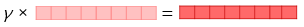
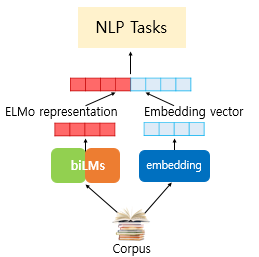
- 이렇게 완성된 벡터를 ELMo 표현 이라고 함.
- 이제 ELMo를 입력으로 사용하여 수행하고 싶은 텍스트 분류, 질의 응답 시스템 등의 자연어 처리 작업을 시행.
- ELMo 표현을 기존의 임베딩 벡터와 함께 사용.
- 텍스트 분류 작업을 위해 GloVe와 같은 기존의 방법론을 사용한 임베딩 벡터를 준비했다고 할 때,
- 준비된 ELMo 표현을 GloVe 임베딩 벡터와 연결(Concatenate)해서 입력으로 사용.
- 이때 biLM의 가중치는 고정시키고, 위에서 사용한 s1,s2,s3, r 은 훈련 과정에서 학습.
BERT(Bidirectional Encoder Representations from Transformers)
- 2018년 10월 논문 공개, 11월 오픈소스 공개로 혜성처럼 등장한 구글의 새로운 Language Representation Model.
- 대형 코퍼스로 Unsupervised Learning을 통해 General Purpose Language Understanding Model을 구축.
- 이후 실행하고자 하는 Task에 집중한 데이터로 Supervised Learning 하여 적용하는 Semi-Supervised Model.
- ELMo와 같이 양방향 문맥을 모두 고려하는 방식으로 접근.
- 다만 ELMo는 Shallow Bidirectional 방식으로 사용했으므로 보다 Deep한 접근법이 필요.
자세한 설명은 이전글 첨부.
'자연어처리' 카테고리의 다른 글
| 한국어 임베딩(이기창 저. 2019) / Chapter 2. How Vector Becomes Meaningful (0) | 2022.08.06 |
|---|---|
| 한국어 임베딩(이기창 저. 2019) / Chapter 1. Introduction (0) | 2022.08.06 |
| BERT의 마스크드 언어 모델(Masked Language Model) (0) | 2022.06.08 |
| 버트(Bidirectional Encoder Representations from Transformers, BERT) (0) | 2022.06.07 |
| NLP에서의 사전 훈련(Pre-Training) (0) | 2022.06.03 |


