
Zorba blog
분류 (classification) / 이진 분류기, 다중 분류기의 성능 평가 방법 본문
분류기의 성능 평가는 여러번 읽어지만 헷갈리는 것이 정말 많은 주제중에 하나입니다. 특히 정밀도, 재현율, 민감도 등 한글로 보았을 때 의미와 매칭되지 않기 때문에 볼 때 마다 헷갈리고는 합니다. 이번 기회에 다시 한번 정리해보고자 합니다.
이진 분류기의 성능 평가
이진 분류기의 성능을 평가하는 좋은 방법은 오차 행렬(Confusion Matrix)를 조사하는 것입니다. 오차 행렬의 행은 실제 클래스를 나타내고, 열은 예측한 클래스를 나타냅니다. 아래 표와같이 왼쪽 위는 실제 음성을 음성으로 올바르게 예측한 결과이고, 그 오른쪽은 실제 음성을 양성으로 잘못 예측한 경우 입니다.

오차 행렬이 많은 정보를 제공해주지만 가끔 더 요약된 지표가 필요할 때도 있습니다. 먼저 살펴볼 만한 것 하나는 양성 예측의 정확도입니다. 이를 분류기의 정밀도(Precision) 라고 합니다. (정밀도 : 양성이라고 예측한 것들에 대해 얼마나 정확하게 예측하였는가)
정밀도 = TP/(TP+FP)
TP는 진짜 양성의 수이고, FP는 거짓 양성의 수입니다. 정밀도는 재현율(Recall)이라는 또 다른 지표와 같이 사용하는 것이 일반적입니다. 재현율은 분류기가 정확하게 감지한 양성샘플의 비율로 민감도(Sensitivity) 또는 진짜 양성 비율(True Positive Rate, TPR) 이라고도 합니다. (재현율 : 실제로 양성으로 예측한 것들중에 음성으로 잘못 예측해서 빼먹은 것은 없는가)
재현율 = TP/(TP+FN)
FN은 거짓 음성의 수입니다.
정밀도와 재현율을 F1 점수(F1 Score)라고 하는 하나의 숫자로 만들면 편리합니다. 특히 두 분류기의 성능을 비교할 때 그렇습니다. F1 점수는 정밀도와 재현율의 조화 평균을 통해 구합니다.

정밀도와 재현율의 값이 비슷한 분류기에서는 F1 점수가 높습니다. 하지만 F1 점수가 높다고 바람직한 것은 아닙니다. 상황에 따라 정밀도가 더 중요할 수도, 재현율이 더 중요할 수도 있습니다. 예를 들어 어린아이에게 안전한 동영상을 걸러내는 분류기를 훈련시킨다고 가정해보겠습니다. 재현율이 높은 경우 정말 나쁜 동영상이 노출될 수 있기에, 좋은 동영상이 많이 제외되더라도(낮은 재현율) 안전한 것들만 노출시키는(높은 정밀도) 분류기를 선호할 것입니다.
정밀도/재현율 트레이드오프
분류기를 결정 함수(decision function)을 사용하여 각 샘플의 점수를 계산합니다. 이 점수가 임계값보다 크면 샘플을 양성 클래스에 할당하고, 그렇지 않으면 음성 클래스에 할당합니다. 임계값이 높을수록(양성으로 예측하는데 타이트할수록) 정밀도는 높아지고, 재현율은 낮아집니다. (운좋게, 간당간당하게 맞힌 애들을 다 못 맞는걸로 처리하다보니. 재현율이 낮아짐. 반면에 확실해지기 때문에 정밀도는 높아짐.) 반대로 임계값을 내리면 정밀도는 낮아지고, 재현율은 높아집니다.
그렇다면 적절한 임곗값을 어떻게 정할 수 있을까요? 이를 위해서는 먼저 모든 임계값에 대해 정밀도와 재현율을 계산해야 합니다. 좋은 정밀도/재현율 트레이드오프를 선택하는 방법은 재현율에 대한 정밀도 곡선을 그리는 것입니다. 그림을 보면 특정 재현율 근처에서 정밀도가 급격하게 줄어들기 시작합니다. 이 하강점 직전을 정밀도/재현율 트레이드오프로 선택하는 것이 좋습니다.

만약 정밀도 90%를 달성하는 것이 목표라면, 이에따른 임계값을 찾을 수 있고, 재현율 또한 구할 수 있습니다. (누군가가 "99% 정밀도를 달성하자" 라고 말하면 반드시 "재현율 얼마에서?" 라고 물어봐야 합니다.)
ROC 곡선
ROC(receiver operating characteristic) 곡선도 이진 분류에서 널리 사용하는 도구입니다. 정밀도/재현율 곡선과 매우 비슷하지만, ROC 곡선은 정밀도에 대한 재현율 곡선이 아니고 거짓 양성 비율(False Positive Rate, FPR)에 대한 진짜 양성 비율(True Positive Rate, TPR) 의 곡선입니다. FPR은 양성으로 잘못 분류된 음성 샘플의 비율이며, 1에서 음성으로 정확하게 분류한 음성 샘플의 비율인 진짜 음성 비율(TNR)을 뺀 값입니다. TNR을 특이도(Specificity)라고도 합니다. 그러므로 ROC 곡선은 민감도(재현율)에 대한 1-특이도 그래프입니다.
여기에서도 트레이드오프가 있습니다. 재현율(TPR)이 높을수록 분류기가 만드는 거짓 양성 비율(FPR)이 늘어납니다.
곡선 아래의 면적(Area Under the Curve, AUC)을 측정하면 분류기들을 비교할 수 있습니다. 완벽한 분류기는 ROC의 AUC가 1이고, 완전한 랜덤 분류기를 0.5 입니다.
| ROC 곡선이 정밀도/재현율 곡선과 비슷해서 어떤것을 사용해야 할지 궁금할 수 있습니다. 일반적인 법칙은 양성 클래스가 드물거나 거짓 음성보다 거짓 양성이 더 중요할 때 정밀도/재현율 곡선을 사용하고 그렇지 않으면 ROC 곡선을 사용합니다. |
다중 분류기의 성능 평가
이중 분류가 두 개의 클래스를 구별하는 반면 다중 분류기는 둘 이상의 클래스를 구별할 수 있습니다. (SGD 분류기, 랜덤 포레스트 분류기, 나이브 베이즈 분류기 같은) 일부 알고리즘은 여러 개의 클래스를 직접 처리할 수 있는 반면, 다른 알고리즘(로지스틱 회귀나 서포트 벡터 머신 분류기) 은 이진 분류만 가능합니다. 하지만 이진 분류기를 여러 개 사용해 다중 클래스를 분류하는 기법도 많습니다.
예를 들어 특정 숫자 하나만 구분하는 숫자별 이진 분류기 10개를 훈련시켜 클래스가 10개인 숫자 이미지 분류 시스템을 만들 수 있습니다. 이를 OvR(One-Versus-The-Rest) 전략이라고 합니다. 또는 OvA(One-Versus-All)라고도 부릅니다.
또 다른 전략은 0과 1구별, 0과 2구별 등과 같이 각 숫자의 조합마다 이진 분류기를 훈련시키는 것입니다. 이를 OvO(One-Versus-One) 전략이라고 합니다. Mnist 문제에서는 0~9까지 분류를 하기 때문에 45개의 분류기를 훈련시켜야 합니다.
에러 분석
실제 프로젝트라 가정하고, 만약 가능성이 높은 모델 하나를 찾았다고 할 때 이 모델의 성능을 향상시킬 방법을 찾아보겠습니다. 한 가지 방법은 만들어진 에러의 종류를 분석하는 것입니다. 다중 분류기에서 오차 행렬을 그려보겠습니다.
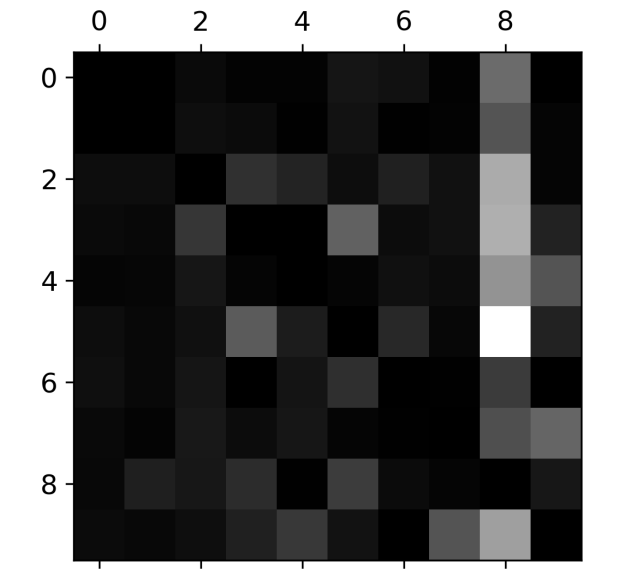
오차 행렬은 대부분의 이미지가 올바르게 분류되었음을 나타내는 주대각선에 있으므로 매우 좋아보입니다. 그래프의 에러 부분에 초점을 맞춰보겠습니다. 먼저 오차 행렬의 각 값을 대응되는 클래스의 이미지 개수로 나누어 에러 비율을 비교합니다. (행 단위인 실제 클래스별로 개수를 sum하여 해당 값으로 나눔)
해당 차트를 보면 어떤 클래스에서 어떤 값으로 잘못 예측하였는지 확인할 수 있습니다. 예를 들면 클래스 8의 열이 상당히 밝으므로 많은 이미지가 8로 잘못 예측하였다고 볼 수 있고, 그중 5에서 제일 잘못 예측한 것을 확인할 수 있습니다.
오차 행렬을 분석하면 분류기의 성능 향상 방안에 대한 통찰을 얻을 수 있습니다. 위 같은 경우 8로 잘못 분류되는 것을 줄이도록 개선할 필요가 있습니다. 이를 위해 8처럼 보이는 숫자의 데이터를 더 많이 모아서 실제 8과 구분하도록 분류기를 학습시킬 수도 있습니다. 또는 분류기에 도움 될 만한 특성을 더 찾아볼 수 있습니다. 예를 들어 동심원의 수를 세는 알고리즘을 도입하여 해당 산출물을 input으로 추가거나 전처리해볼 수도 있습니다.
다중 레이블 분류
분류기가 샘플마다 여러 개의 클래스를 출력해야 할 때도 있습니다. 이처럼 여러 개의 이진 꼬리표를 출력하는 분류 시스템을 다중 레이블 분류 시스템이라고 합니다. 예를 들어 숫자 이미지를 입력하였을 때 어떤 숫자인지 맞추는 것이아니라 1) 6보다 큰지 2) 홀수인지 이처럼 다중 타깃을 맞추도록 하는 것 입니다.
다중 레이블 분류기를 평가하는 방법은 많습니다. (적절한 지표는 프로젝트에 따라 다릅니다.) 예를 들어 각 레이블의 F1 점수를 구하고 간단하게 평균 점수를 계산할 수 있습니다. 이는 모든 레이블의 가중치가 같다고 가정한 것입니다. 간단한 방법은 레이블에 클래스의 지지도(타깃 레이블에 속한 샘플 수)를 가중치로 주는 것입니다.
다중 출력 분류
마지막으로 알아볼 분류 작업은 다중 출력 다중 클래스 분류 입니다. 다중 출력 분류 문제의 예를 들어보면 이미지 잡음을 제거하는 시스템이 있습니다. 잡음이 많은 숫자 이미지를 입력으로 받고 깨끗한 숫자 이미지를 MNIST 이미지처럼 픽셀의 강도를 담은 배열로 출력합니다. 분류기의 출력이 다중 레이블이고, 각 레이블은 값을 여러개 가집니다(0부터 225까지 픽셀 강도.)
이 다중 출력 분류 시스템을 통해 잡음이 섞인 숫자 이미지를 입력하였을 때 깨끗한 숫자 이미지를 출력으로 얻을 수 있습니다.
'Machine Learning' 카테고리의 다른 글
| LSTM and GRU(Long Short Term Memory & Gated Recurrent Unit) (0) | 2022.08.06 |
|---|---|
| Gradient Descent Optimization Algorithms (0) | 2022.06.23 |
| 앙상블(Ensemble) / Bagging, Boosting, Stacking (0) | 2022.06.22 |
| 서포트 벡터 머신 (Support Vector Machine, SVM) (0) | 2022.05.16 |
| Decision Tree (결정 트리) (0) | 2022.05.16 |

